

在Zabbix监控实践中,您是否遇到过监控项时而正常、时而失效的“玄学”问题?手动测试一切正常,但自动采集却间歇性失败。本文将由一个真实的云平台监控案例入手,深入剖析如何通过自定义监控项的调度间隔(Scheduling) 这一强大功能,精准避开数据获取的故障时间窗口,实现监控执行的“错峰出行”。
背景:
在对接某云平台的监控数据时,发现部分监控项无法正常获取数据,但手动执行对应脚本可成功获取。初步排查执行用户权限问题,切换 Agent 执行用户后脚本仍能正常返回。进一步分析发现,监控项仅在每分钟的 20 秒至 59 秒之间执行才能成功获取数据,而在每分钟的前 20 秒执行则频繁失败。该现象可能与云平台内部机制有关,为避免该问题,需调整监控项执行时间,避开每分钟的前 20 秒。
解决方案:
通过配置监控项的自定义调度间隔,将执行时间固定在每分钟的 20 秒之后,以规避数据获取失败的问题。
现在拿一台主机中的某个监控项为例:
1.现在这台主机的ping检查,设置的就是一分钟的采集间隔。
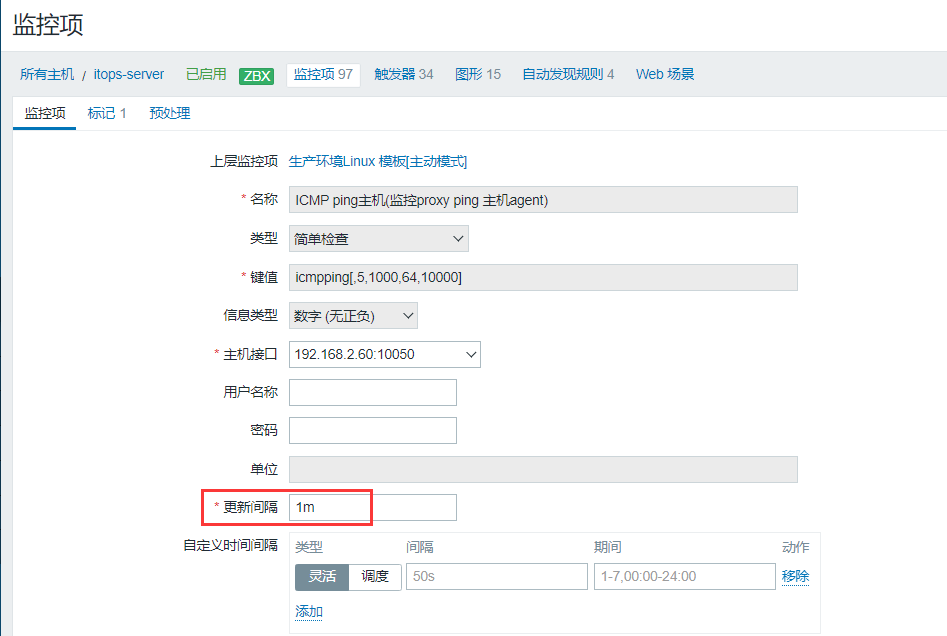
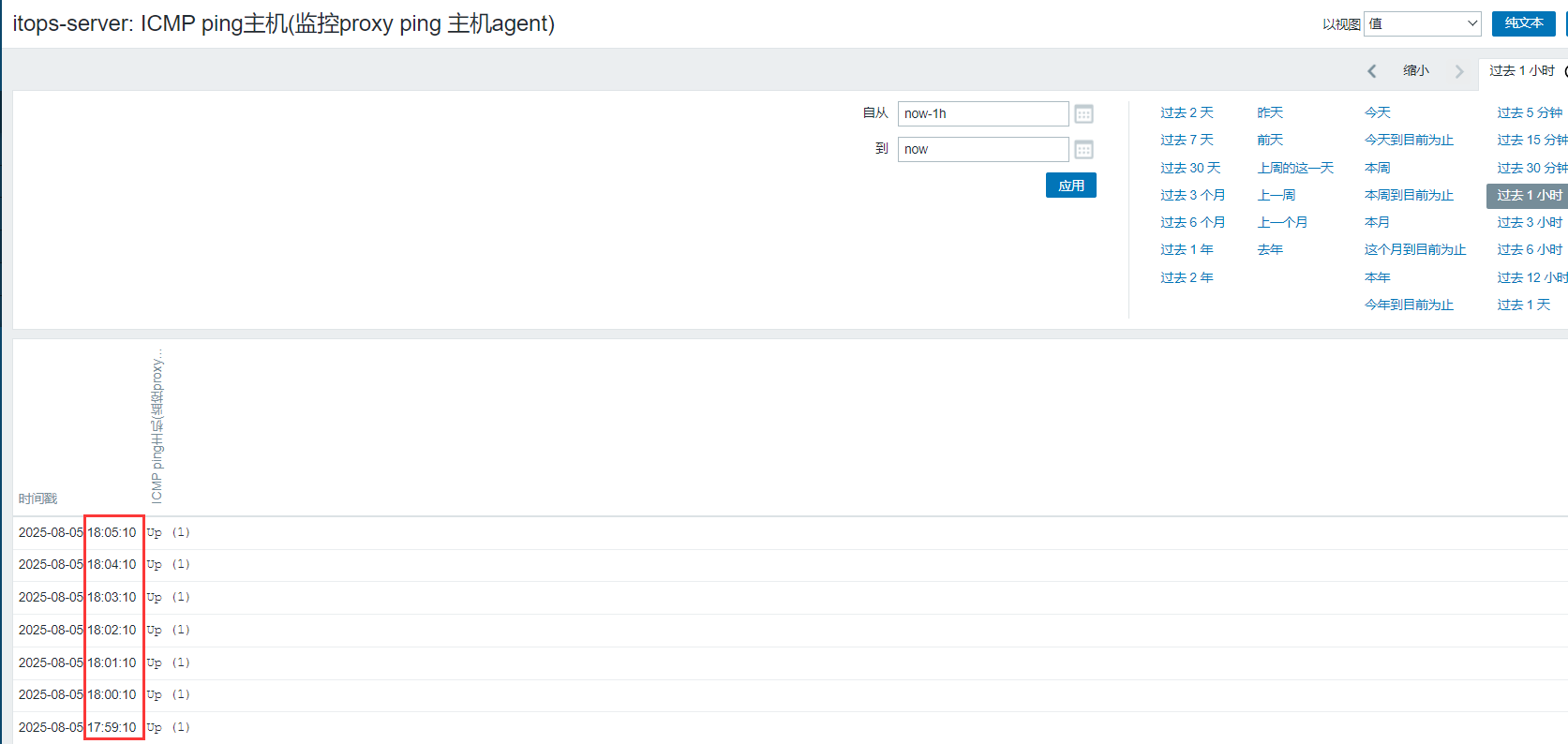
可以看到这个监控项的采集时间是每分钟的第10秒。通常像这种具体的时间点分配是系统默认调度行为,系统会自动将相同间隔的监控项的执行时间错开,目的是避免所有监控项在同一时刻并发执行,提升系统性能和稳定性。
2.如需指定具体执行时间点可以在监控项中的自定义时间间隔中配置“调度”模式。
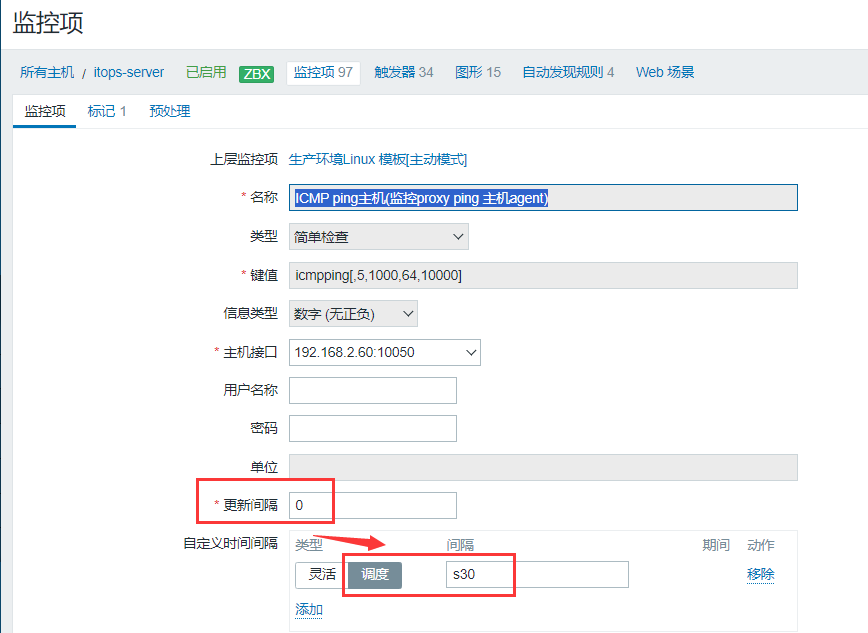
更新间隔改为0,意思是不再用这个间隔来定义取值时间。若沿用之前的1m,那每隔一分钟之后仍会取得一个值。
自定义时间间隔选择“调度”,间隔框内写s30,意思是每分钟的第30秒执行取值。
另外需要注意的是调度的方式只能用于被动模式类型的监控项(即是由proxy或者server发起请求的类型,如“简单检查”、“Zabbix客户端”这种类型),而不能用于主动式类型的监控项(即是由监控对象主动推送数据到proxy或者server的类型,如“Zabbix客户端(主动式)”)。
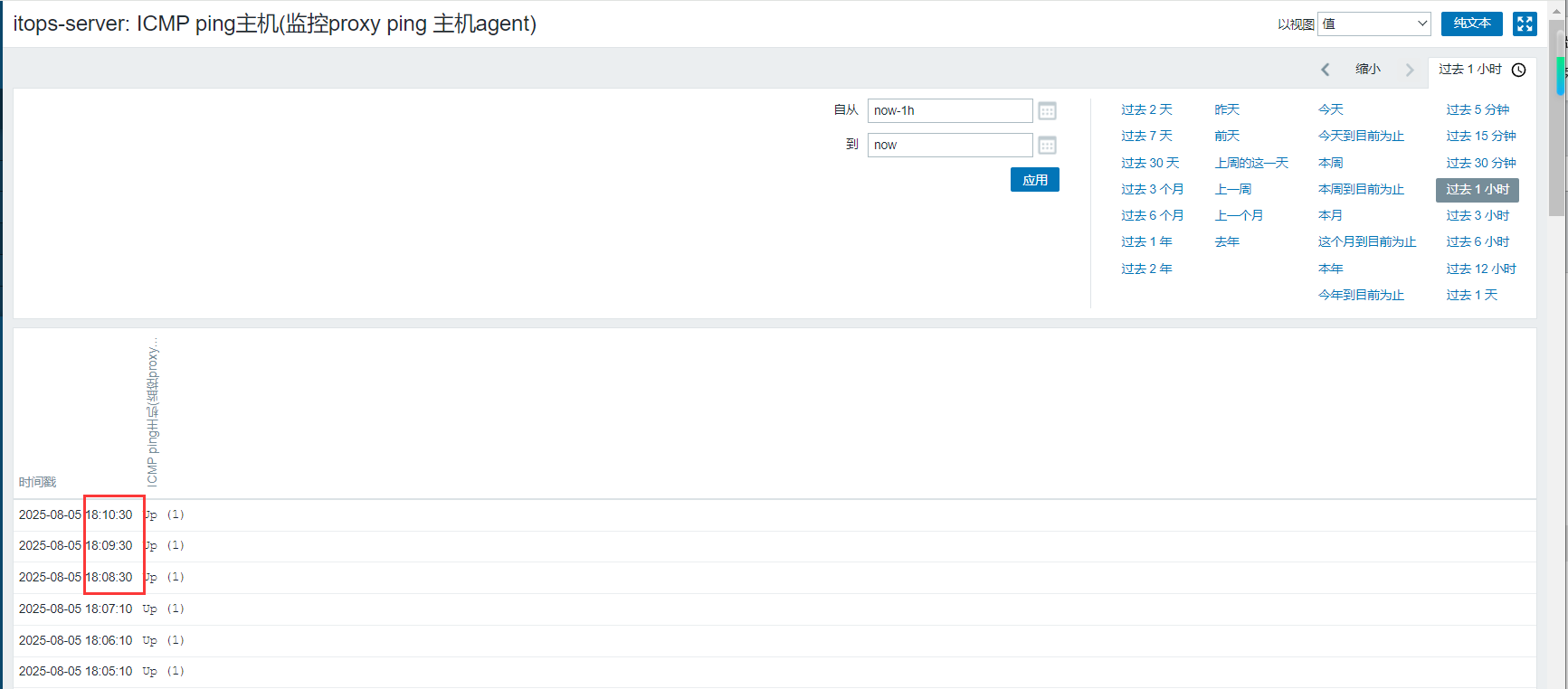
3.经过取值刷新以后,再查看监控项的取值具体时间,可以看到现在的取值变为固定的每分钟第30秒。
关于调度的取值配置说明:
调度的取值过滤器前缀的有效 <from> 和 <to> 值分别为:
| 前缀 | 描述 | <from> | <to> |
| md | Month days | 1-31 | 1-31 |
| wd | Week days | 1-7 | 1-7 |
| h | Hours | 0-23 | 0-23 |
| m | Minutes | 0-59 | 0-59 |
| s | Seconds | 0-59 | 0-59 |
● md为月,有效值为1-31
● wd为周,有效值为1-7
● h为时,有效值为0-23
● m为分,有效值是0-59
● s为秒,有效值是0-59
实际上是调度的执行间隔写法很灵活,以下是调度方式的取值间隔写法参考:
| m0-59 | 每分钟执行一次 |
| h9-17/2 | 从9:00开始每2小时执行一次(9:00,11:00 ...) |
| m0,30 or m/30 | 在每小时的hh:00 和 hh:30执行 |
| m0,5,10,15,20,25,30,35,40,45,50,55 or m/5 | 每5分钟执行 |
| wd1-5h9 | 每周一至周五9:00 |
| wd1-5h9-18 | 每个星期一到星期五在9:00,10:00,...,18:00 |
| h9,10,11 or h9-11 | 每天上午9:00,10:00和11:00 |
| md1h9m30 | 每个月的第一天在9:30 |
| md1wd1h9m30 | 如果是星期一,每个月的第一天在9:30执行 |
| h9m/30 | 在9:00,9:30执行 |
| h9m0-59/30 | 在9:00,9:30执行 |
| h9,10m/30 | 在9:00,9:30,10:00,10:30执行 |
| h9-10m30 | 在9:30,10:30执行 |
| h9m10-40/30 | 在9:10,9:40执行 |
| h9,10m10-40/30 | 在9:10,9:40,10:10,10:40执行 |
| h9-10m10-40/30 | 在9:10,9:40,10:10,10:40执行 |
| h9m10-40 | 在9:10,9:11,9:12,... 9:40执行 |
| h9m10-40/1 | 在9:10,9:11,9:12,... 9:40执行 |
| h9-12,15 | 在9:00,10:00,11:00,12:00,15:00执行 |
| h9-12,15m0 | 在9:00,10:00,11:00,12:00,15:00执行 |
| h9-12s30 | 在9:00:30,9:01:30,9:02:30 ... 12:58:30,12:59:30执行 |
| h9m/30;h10 (API-指定语法) | 在9:00,9:30,10:00执行 |