

| Q:如何让告警一直在主面板显示,除非我人工确认 A:选择最近问题,可以看到最近的所有问题,包括已恢复的问题 |
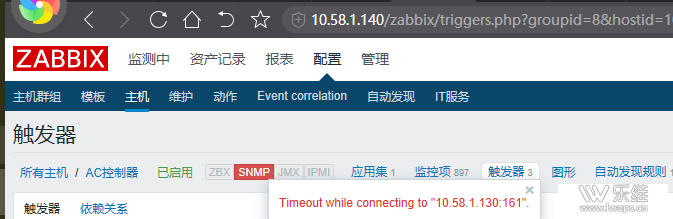
Q:【问题现象】 我的wlc host经常Timeout while connecting to "10.58.1.130:161".应该如何排查? 【问题前操作】 zabbix 通过自动发现检测到wlc上的800多ap,频率为5分钟。发现后,问题出现 【已做排查】 出现问题时,zabbix snmpwalk 能取到wlc 的ap信息。 |
A:zabbix_server.conf上设置的超时时间是多少? Q:4 |

A:可以改为30,重启zabbix服务后看下是否还有这个问题。 Q:配置更改后已重启,问题还未恢复,还需要作其他操作吗? A:需要等待监控项成功获取一次数据才会变成绿色。如果需要排查问题,需要在最新数据界面,找一下是否有部分监控项到了时间间隔,但是数据却没更新的。 Q:部分监控获取到了数据。另snmp监控 ap设置的5分钟间隔已过去 |
A:你的自动发现规则是怎么配置的? Q: |
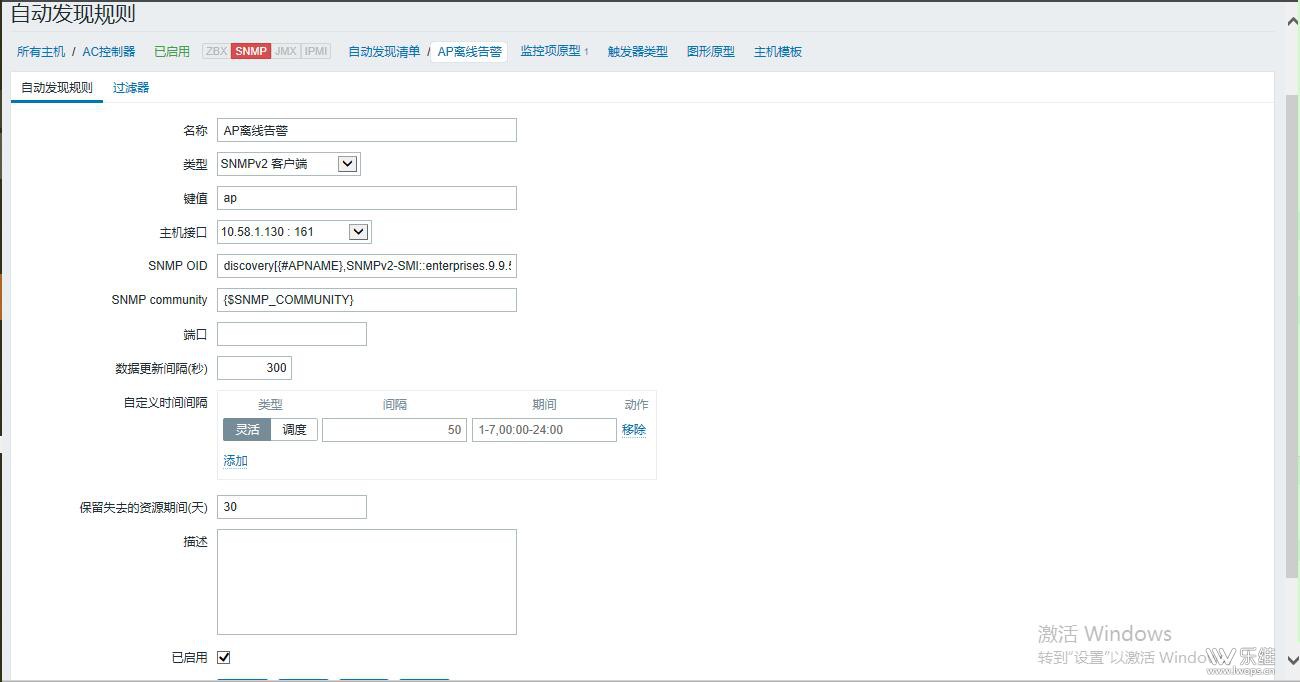
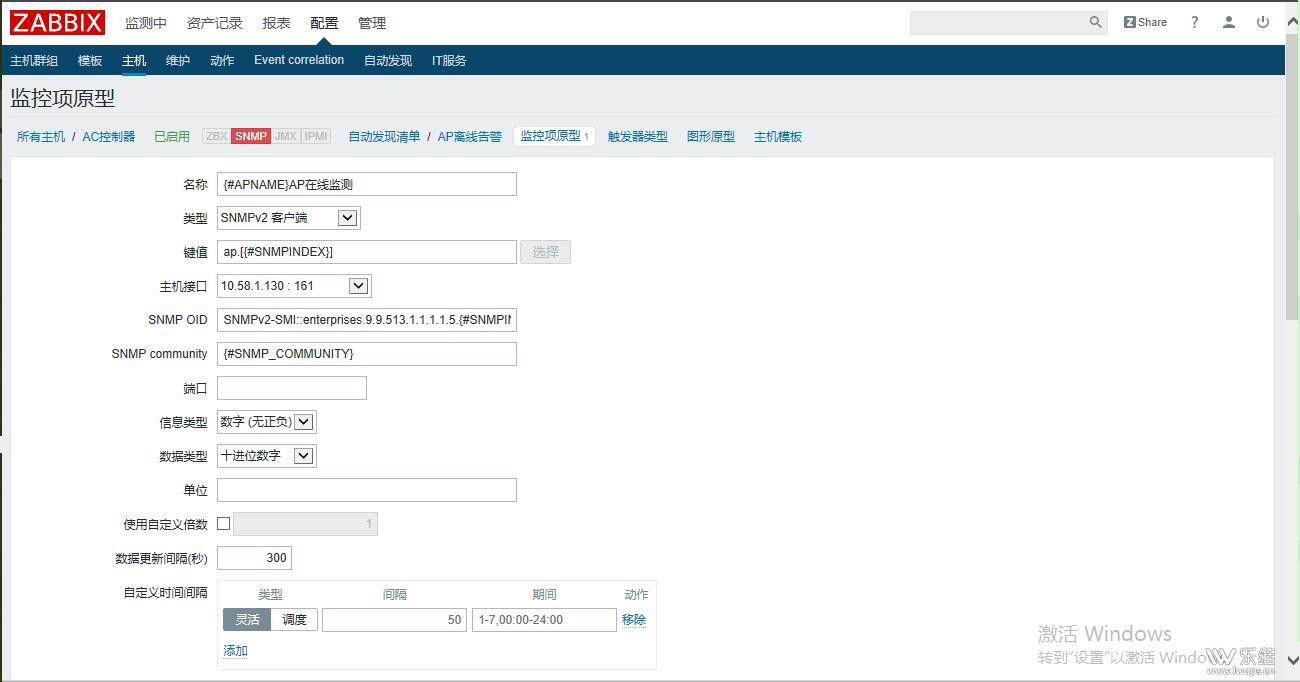
A:那个自动发现规则里的snmp OID的内容可以复制出来吗? Q:SNMPv2-SMI::enterprises.9.9.513.1.1.1.1.5.{#SNMPINDEX} A:是第一张图的那个snmp OID的全部内容,我感觉是写错了 Qdiscovery[{#APNAME},SNMPv2-SMI::enterprises.9.9.513.1.1.1.1.5] ,这是第一张的 A:snmpwalk 这个OID返回的结果是怎样的? |
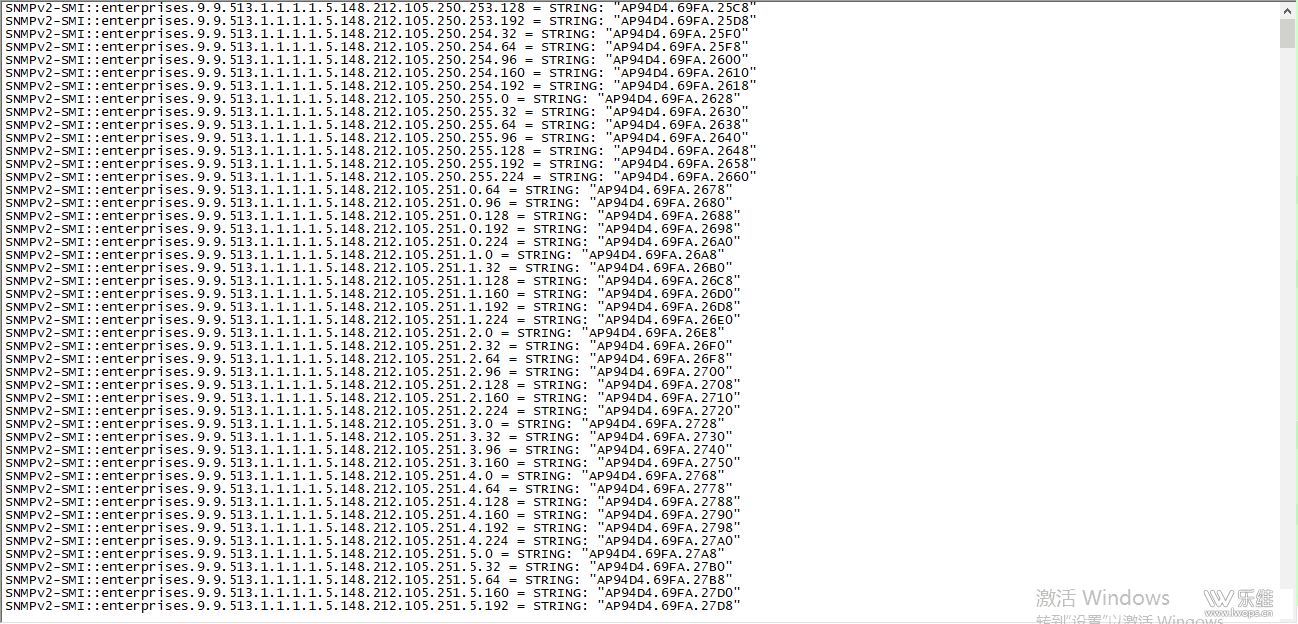
Q:snmpwalk -v 2c -c public 10.58.1.130 enterprises.9.9.513.1.1.1.1.5 A:snmpwalk -v 2c -c public 10.58.1.130 enterprises.9.9.513.1.1.1.1.5.0.162.137.0.134.224 这个有数据吗? |
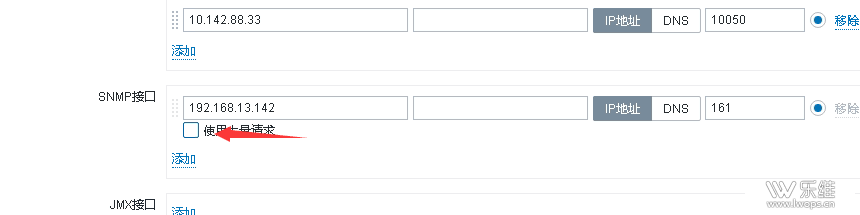
还可以试下不勾选 使用大量请求 这个选项,使用大量请求 这个选项再等5分钟左右看下吧 Q大量请求取消也已测过了,之前就取消了。 A:zabbix的日志有相关的信息吗? Q:没看到相关信息 |

监控单个AP oid正常,是不是snmp批量通信问题? A:是的,是真的有800多个AP在线吗? Q:是的,有优化的资料没? |
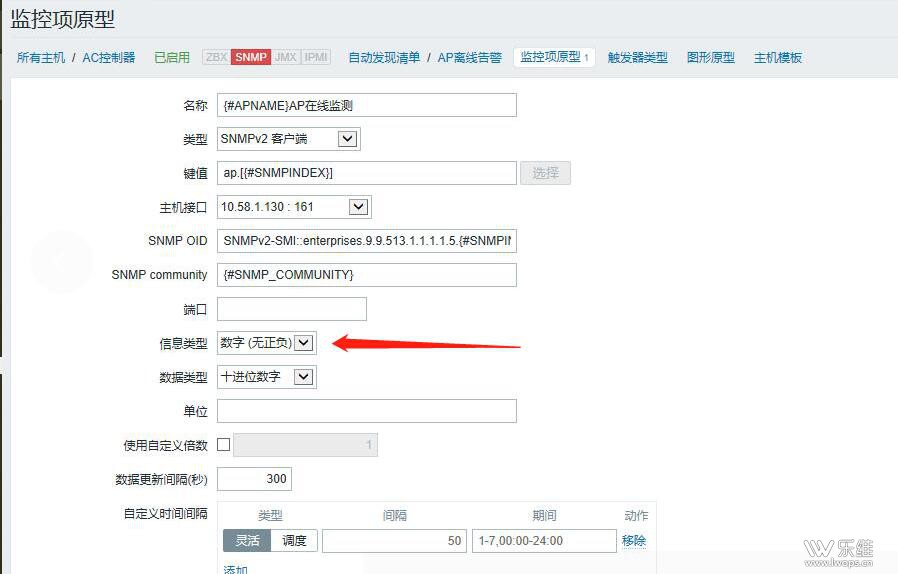
A:信息类型是字符来的,可以禁用一部分监控项,测试是否能够获取数据,如果能够获取数据,说明是同一时间获取的量太多导致,确定是这个问题后,如果还是只想通过zabbix的snmp监控,只能调整监控项的时间间隔。其他解决办法:可以通过脚本配合zabbix_sender,时间间隔5分钟获取一次数据。 Q:日志提示临时性关闭snmp agent,zabbix 能实现错峰收集自动发现的800AP信息吗? A:目前还做不到 Q:自动发现网络接口过滤的那个后面的数字代表什么 1 2 3 5 7 |
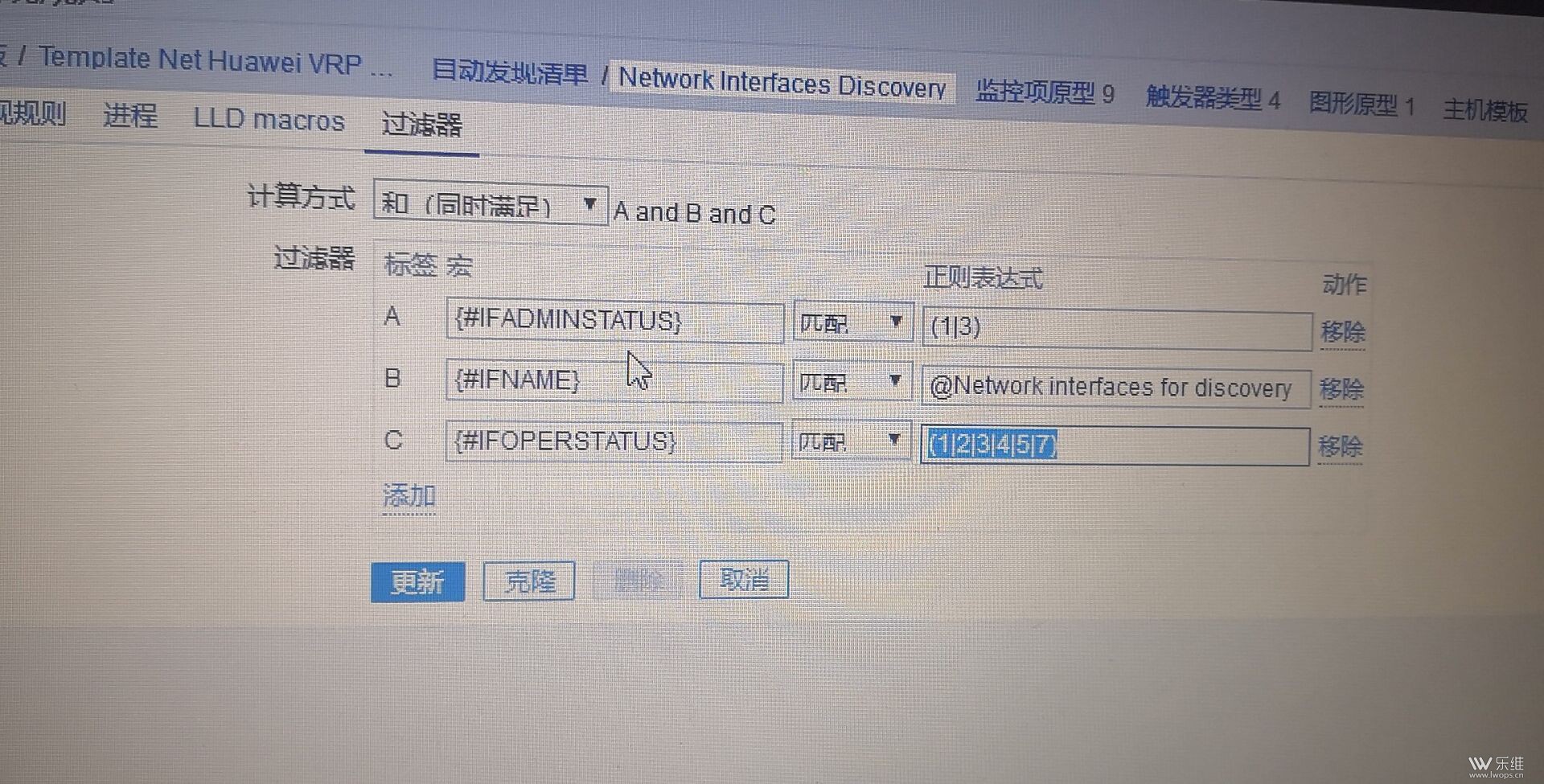
A:对{#IFOPERSTATUS}这个宏的值进行过滤,只要值为1、2、3、4、5、7的 |
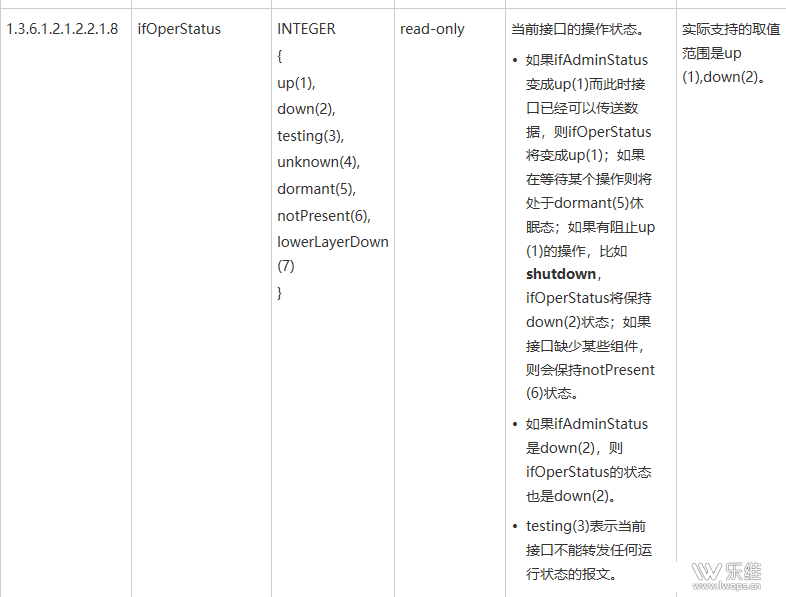
Q:生产环境中会在发现网络接口里过滤吗?如果过滤了down的下次发现接口刚好down那中间就会没有接口的数据吧 A:如果之前是up,自动发现接口down了以后,down的接口监控项会保留一段时间,这段时间里自动发现不了后,再删除,保留多长时间可以在自动发现规则里设置。如果之前是down的,接口up了之后,需要等自动发现时间间隔到了之后生成,这段时间没有监控数据。 |

https://support.huawei.com/enter ... e-12800-pid-7542409 这些信息,对应的设备的mib文件里会说明的,接口mib属于公有mib,所以其他设备的mib也能看到 Q:交换机流量的收发方向这样是正确的吗? |
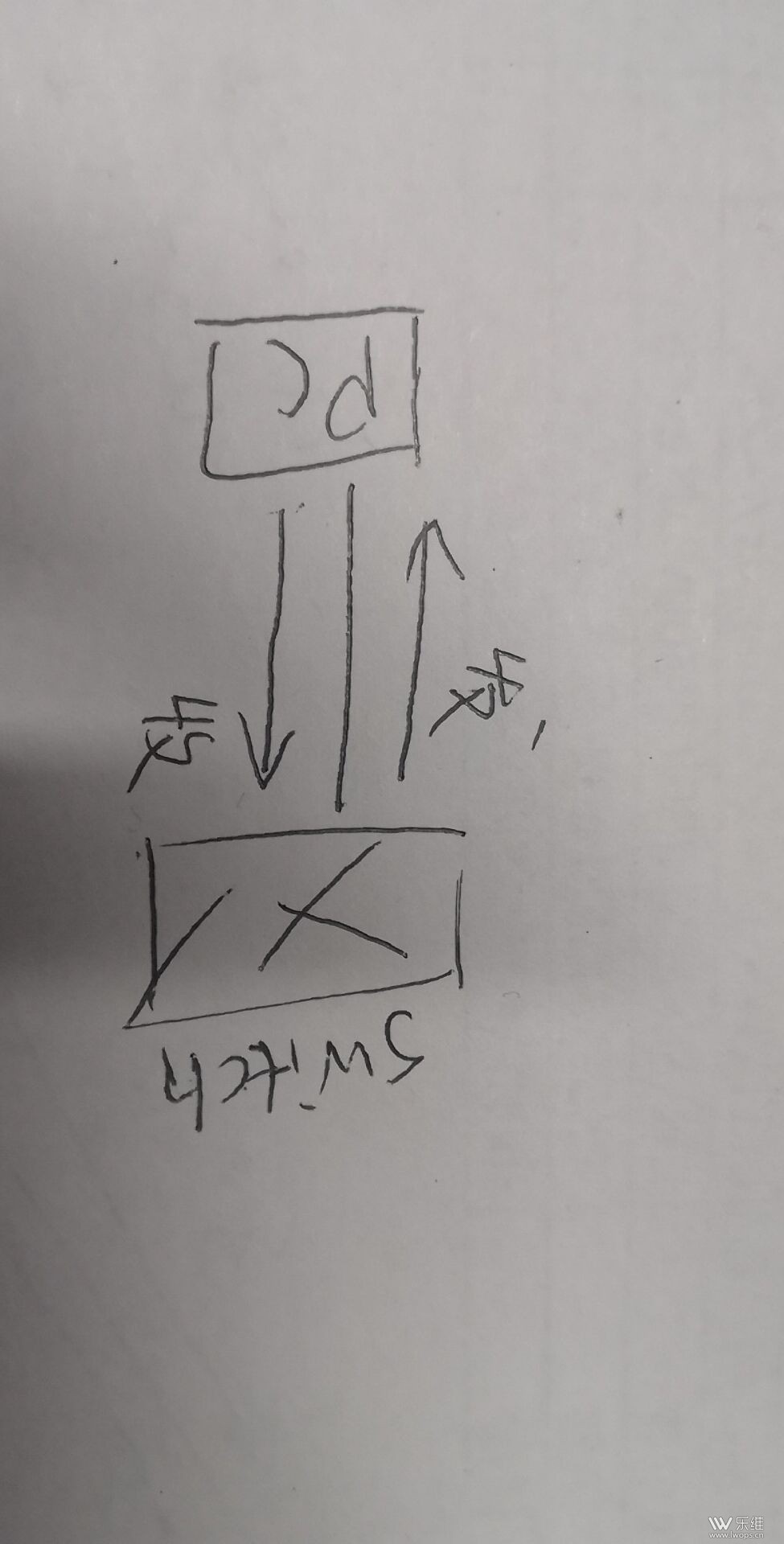
A:对的 本期待解决问题: 请问,我的一个windows server 2003主机,zabbix里经常出现cpu使用率超出100%的数据,这是什么原因啊? |
